Analyzing Negation Sentiments with NLP
Introduction
Throughout various industries, Natural Language Processing (NLP) models can be used to solve many problems: organizations can use NLP analysis to understand employee satisfaction; companies can use NLP to understand consumer sentiment for a project; investments firms can use NLP to understand the market’s sentiment around a specific stock or company. By performing NLP, organizations can gain quantitative insights from qualitative data.
One problem that currently faces the field is analyzing sentiment when negations are present. For example, the sentence “Don’t do that again!” can be interpreted in a positive context (if, for example, a person pranked another person) or in a negative context (if a person caused harm to another person). Denials, imperatives, questions, and rejections are all forms have negations that can decrease accuracy. Ultimately, creating a model that can determine sentiment with negations present is important as organizations can use this model alongside other models to gain more accurate insights.
With this in mind, my project aims at developing a model that analyzes sentiment analysis with negations present. By analyzing tweets that specifically contain any or all of the words “no”, “not”, “never”, and “didn’t”, I attempt to build a machine learning model that can accurately classify these sentiments as either positive or negative.
Tools
I will be creating these models using Python. In particular, I will be using the pandas and numpy libraries to clean the data, the sklearn library to prepare the data, and keras to build and train the models. I also use the nltk library to provide stopwords.
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import text_to_word_sequence
from tensorflow.keras.preprocessing.text import Tokenizer
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import nltk
from nltk.corpus import stopwords
nltk.download('punkt')
nltk.download('brown')
nltk.download('stopwords')
stop = stopwords.words('english')
stop = set(stopwords.words('english')) - {'no', 'not','never',"don't",'never','nor'}
When preparing data for NLP, commonly used words, such as “our”, “such”, and “out”, are typically removed from datasets as these are words that do not provide the true sentiment regarding a statement. For this project, I am making sure to include the negations because I want my model to be able to recognize those words, as shown in redefining the set above.
Data Collection and Preparation
I collected data from Sentiment140, a group run by former Computer Science graduate students at Stanford. They offer machine learning sentiment analysis services on tweets, and offer their training and testing datasets free to use. The datasets contain 6 fields:
- The sentiment of the tweet, where 0 is negative, 2 is neutral, and 4 is positive
- The id of the tweet
- The date of the tweet
- The query of the tweet
- The twitter user who created the tweet
- The text contained in the tweet
First I load the data, and then run value counts to see how much of each sentiment each dataset contains:
df_train = pd.read_csv('training.1600000.processed.noemoticon.csv',encoding='latin-1')
df_test = pd.read_csv('testdata.manual.2009.06.14.csv',encoding='latin-1')
df_train['sentiment'].value_counts().reset_index()
| index | sentiment | |
|---|---|---|
| 0 | 0 | 800000 |
| 1 | 4 | 800000 |
df_test['sentiment'].value_counts().reset_index()
| index | sentiment | |
|---|---|---|
| 0 | 4 | 182 |
| 1 | 0 | 177 |
| 2 | 2 | 139 |
Looking at the datasets, we see that the training datasets have a large number of only negative and positive sentiments and no neutral statements, while the testing datasets have a small number of negative and positive sentiments, and a small number of neutral statements. Because the training dataset does not contain any neutral sentiment tweets nor does the testing dataset contain large numbers of validation data, I decide to drop the neutral tweets from the dataset and combine the two datasets. When building my models, I run a 80/20 split on the training/testing data so that the size of the validation dataset increases.
df_test = df_test[df_test['sentiment']!=2]
df_concat = pd.concat([df_train,df_test],axis=0)
df_concat.head()
| sentiment | user_id | date | query | user | text | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1467810369 | Mon Apr 06 22:19:45 PDT 2009 | NO_QUERY | TheSpecialOne | @switchfoot http://twitpic.com/2y1zl - Awww, that’s a bummer. You shoulda got David Carr of Third Day to do it. ;D |
| 1 | 0 | 1467810672 | Mon Apr 06 22:19:49 PDT 2009 | NO_QUERY | scotthamilton | is upset that he can’t update his Facebook by texting it… and might cry as a result School today also. Blah! |
| 2 | 0 | 1467810917 | Mon Apr 06 22:19:53 PDT 2009 | NO_QUERY | mattycus | @Kenichan I dived many times for the ball. Managed to save 50% The rest go out of bounds |
| 3 | 0 | 1467811184 | Mon Apr 06 22:19:57 PDT 2009 | NO_QUERY | ElleCTF | my whole body feels itchy and like its on fire |
| 4 | 0 | 1467811193 | Mon Apr 06 22:19:57 PDT 2009 | NO_QUERY | Karoli | @nationwideclass no, it’s not behaving at all. i’m mad. why am i here? because I can’t see you all over there. |
Once I combine the datasets, I want to clean them up. First, I make all the letters lowercase so all the words are homogenous. Next, I get rid of twitter usernames and links by filtering out words that contain an “@” and “http”, respectively, as those words do not contain sentiment. I also replace 4 to 1 in the sentiment column as it’s generally good practice.
df_concat['text'] = df_concat['text'].str.lower()
df_concat['text'] = df_concat['text'].apply(lambda x: ' '.join([word for word in x.split() if '@' not in word]))
df_concat['text'] = df_concat['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
df_concat['text'] = df_concat['text'].apply(lambda x: ' '.join([word for word in x.split() if 'http' not in word]))
df_concat['text'] = df_concat['text'].str.replace(r'[^\w\s]','',regex=True)
df_concat['sentiment'] = df_concat['sentiment'].replace(4,1)
df_concat.head()
| sentiment | user_id | date | query | user | text | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1467810369 | Mon Apr 06 22:19:45 PDT 2009 | NO_QUERY | TheSpecialOne | awww thats bummer shoulda got david carr third day |
| 1 | 0 | 1467810672 | Mon Apr 06 22:19:49 PDT 2009 | NO_QUERY | scotthamilton | upset cant update facebook texting might cry result school today also blah |
| 2 | 0 | 1467810917 | Mon Apr 06 22:19:53 PDT 2009 | NO_QUERY | mattycus | dived many times ball managed save 50 rest go bounds |
| 3 | 0 | 1467811184 | Mon Apr 06 22:19:57 PDT 2009 | NO_QUERY | ElleCTF | whole body feels itchy like fire |
| 4 | 0 | 1467811193 | Mon Apr 06 22:19:57 PDT 2009 | NO_QUERY | Karoli | no not behaving im mad cant see |
Now, because I removed the apostrophes in each word, I filter to only contain tweets that contain the words ’no’, ’not’, ’never’, ’never’, or ’nor'.
df_neg = df_concat[df_concat['text'].str.contains(r"no|not|never|didnt|dont|nor",regex=True)]
df_neg = df_neg.reset_index()
df_neg.head()
| index | sentiment | user_id | date | query | user | text | |
|---|---|---|---|---|---|---|---|
| 0 | 4 | 0 | 1467811193 | Mon Apr 06 22:19:57 PDT 2009 | NO_QUERY | Karoli | no not behaving im mad cant see |
| 1 | 5 | 0 | 1467811372 | Mon Apr 06 22:20:00 PDT 2009 | NO_QUERY | joy_wolf | not whole crew |
| 2 | 7 | 0 | 1467811594 | Mon Apr 06 22:20:03 PDT 2009 | NO_QUERY | coZZ | hey long time no see yes rains bit bit lol im fine thanks hows |
| 3 | 8 | 0 | 1467811795 | Mon Apr 06 22:20:05 PDT 2009 | NO_QUERY | 2Hood4Hollywood | nope |
| 4 | 10 | 0 | 1467812416 | Mon Apr 06 22:20:16 PDT 2009 | NO_QUERY | erinx3leannexo | spring break plain city snowing |
Class Imbalance
When performing a classification analysis, it is important to make sure that the classes you are differentiating are of similar magnitude, i.e. balanced. I will visually check this by plotting the number of negative and positive tweets below.
x_count = list(df_neg['sentiment'].unique())
y_count = list(df_neg['sentiment'].value_counts())
fig = plt.figure(figsize = (12, 8))
# creating the bar plot
plt.bar(x_count, y_count, color ='maroon',
width = .8, tick_label=[0,1])
plt.xlabel("Sentiments")
plt.ylabel("Value Counts")
plt.title("Number of Each Sentiment")
plt.show()
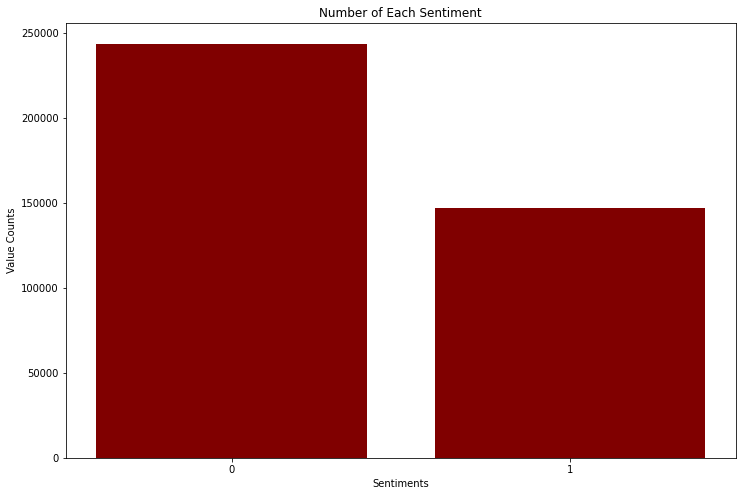
Clearly, the number of negative and positive tweets with negation are on the same order of magnitude, and so the classes are balanced.
Identifying Outliers
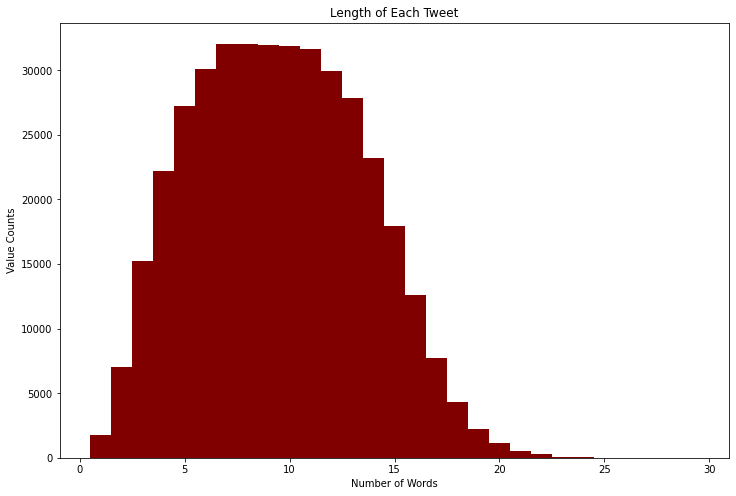
Another step in cleaning the data is to eliminate outliers. If a tweet is too small, then it will not contain enough context to tell us how the negations affect the sentiment. On the other hand, if a tweet is too long, the model can pick up trends that fall outside of how the negations impact the sentiment. Below, I plot the length of each tweet against how frequently that length tweet appears.
df_neg['text'].apply(lambda n: len(n.split())).describe().reset_index()
| index | text | |
|---|---|---|
| 0 | count | 391092 |
| 1 | mean | 9.50027 |
| 2 | std | 4.04891 |
| 3 | min | 1 |
| 4 | 25% | 6 |
| 5 | 50% | 9 |
| 6 | 75% | 13 |
| 7 | max | 29 |
We see that the max length is 29 words, the minimum is 1 word, the average is 9.5 words, the standard deviation is 4.05 words, and the data has a skew of 0.318. To account for the skew and remove outliers, we will make the minimum number of words required in a tweet to be 3 and the maximum number of words required to be 26, which results in a skew of right skewed with a skew of -0.0312.
df_gauss = df_neg[(df_neg['text'].apply(lambda n: len(n.split()))>=3) &
(df_neg['text'].apply(lambda n: len(n.split()))<=26)]
df_gauss['text'].apply(lambda n: len(n.split())).value_counts().reset_index().describe()
| index | text | |
|---|---|---|
| count | 24 | 24 |
| mean | 14.5 | 15929.7 |
| std | 7.07107 | 13442 |
| min | 3 | 12 |
| 25% | 8.75 | 993 |
| 50% | 14.5 | 16573.5 |
| 75% | 20.25 | 29967 |
| max | 26 | 32067 |
x_len_new = list(df_gauss['text'].apply(lambda n: len(n.split())).value_counts().reset_index()['index'])
y_len_new = list(df_gauss['text'].apply(lambda n: len(n.split())).value_counts().reset_index()['text'])
fig = plt.figure(figsize = (12, 8))
plt.bar(x_len_new, y_len_new, color ='maroon',
width = 1)
plt.xlabel("Number of Words")
plt.ylabel("Value Counts")
plt.title("Length of Each Tweet")
plt.show()
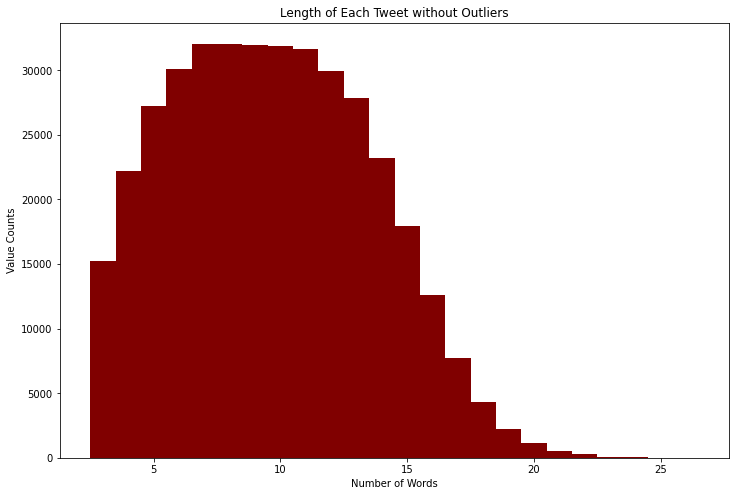
Tokenizing the Data
Now that the data has been cleaned, we need to tokenize it. I tokenize the data with a maximum vocabulary size of 5000, have the max length be the length of the longest tweet, which I restricted to 26, use post padding, and finally join the padded sequences to df_gauss and drop the rest of the columns.
vocab_size = 4000
max_length = df_gauss['text'].apply(lambda n: len(n.split())).max()
myTokenizer = Tokenizer(num_words=vocab_size)
myTokenizer.fit_on_texts(df_concat['text'])
sequences = myTokenizer.texts_to_sequences(df_gauss['text'])
padded = pad_sequences(sequences, maxlen=max_length, padding="post")
df_data = df_gauss.join(pd.DataFrame(padded))
df_data = df_data.drop(['index','user_id','date','query','user','text'],axis=1)
df_data.head()
| sentiment | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 7 | 2 | 303 | 1 | 505 | 182 | 14 | 23 | 213 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 2 | 330 | 2143 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 83 | 93 | 16 | 7 | 23 | 86 | 2481 | 165 | 2454 | 165 | 18 | 1 | 434 | 32 | 715 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 4625 | 764 | 375 | 88 | 241 | 311 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 2178 | 94 | 3919 | 2 | 22 | 67 | 4230 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Preparing the Models
Splitting the Data
When testing the different models and debugging the methods to call the models, I used a subsample of the full dataset for faster debugging. Hence, I created df_sample below. However, for training, I used the full dataset and set frac=1. I then split the data up with an 80/20 split.
df_sample = df_data.sample(frac=0.1,random_state=42)
y = df_sample['sentiment']
X = df_sample.drop('sentiment',axis=1)
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2)
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
Standardizing the Training
There are several steps that can be taken to train the models efficiently. First, instead of running the models locally on my laptop, I can run them in Google Colab, which provides GPUs for faster training. Next, by implementing callbacks, I save the version of each model that I train at every epoch so that I can access a model at any particular moment during its training. These models are saved to a particular folder path in my google drive for later access. I also implement early stopping, which automatically ends training if the models see no improvement in the validation accuracy after 20 epochs. Finally, plots of the loss and accuracy for the testing and validation data are produced.
import datetime
datetime.datetime.today().strftime('%Y-%m-%d_%H:%M:%S')
def fit_model_and_show_results(model, model_name, num_epochs):
date = datetime.datetime.today().strftime('%Y-%m-%d_%H:%M:%S')
checkpoint_filepath = '/content/gdrive/MyDrive/Colab_Notebooks/{folder_path}/'+date+'_weights-{epoch:02d}-{val_accuracy:.3f}.hdf5'
checkpoint_dir = os.path.dirname(checkpoint_filepath)
es = EarlyStopping(monitor='val_accuracy', mode='max', verbose=1, patience=20)
model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath,
save_weights_only=False,
monitor='val_accuracy',
save_freq='epoch')
callbacks_list = [model_checkpoint_callback]
model.summary()
history = model.fit(X_train, y_train, epochs=num_epochs,
validation_data=(X_test, y_test),callbacks=[callbacks_list,es])
plot_graphs(history, model_name, num_epochs)
def plot_graphs(history, model_name, num_epochs):
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_figheight(6)
fig.set_figwidth(16)
fig.suptitle(model_name + ' Accuracy and Loss over '+str(num_epochs) + ' Epochs')
ax1.plot(history.history['accuracy'])
ax1.plot(history.history['val_accuracy'])
ax1.set(xlabel='Epochs', ylabel='Accuracy')
ax1.legend(['accuracy','val_accuracy'])
ax2.plot(history.history['loss'])
ax2.plot(history.history['val_loss'])
ax2.set(xlabel='Epochs', ylabel='Loss')
ax2.legend(['loss','val_loss'])
plt.show()
Training the Models
Simple Model
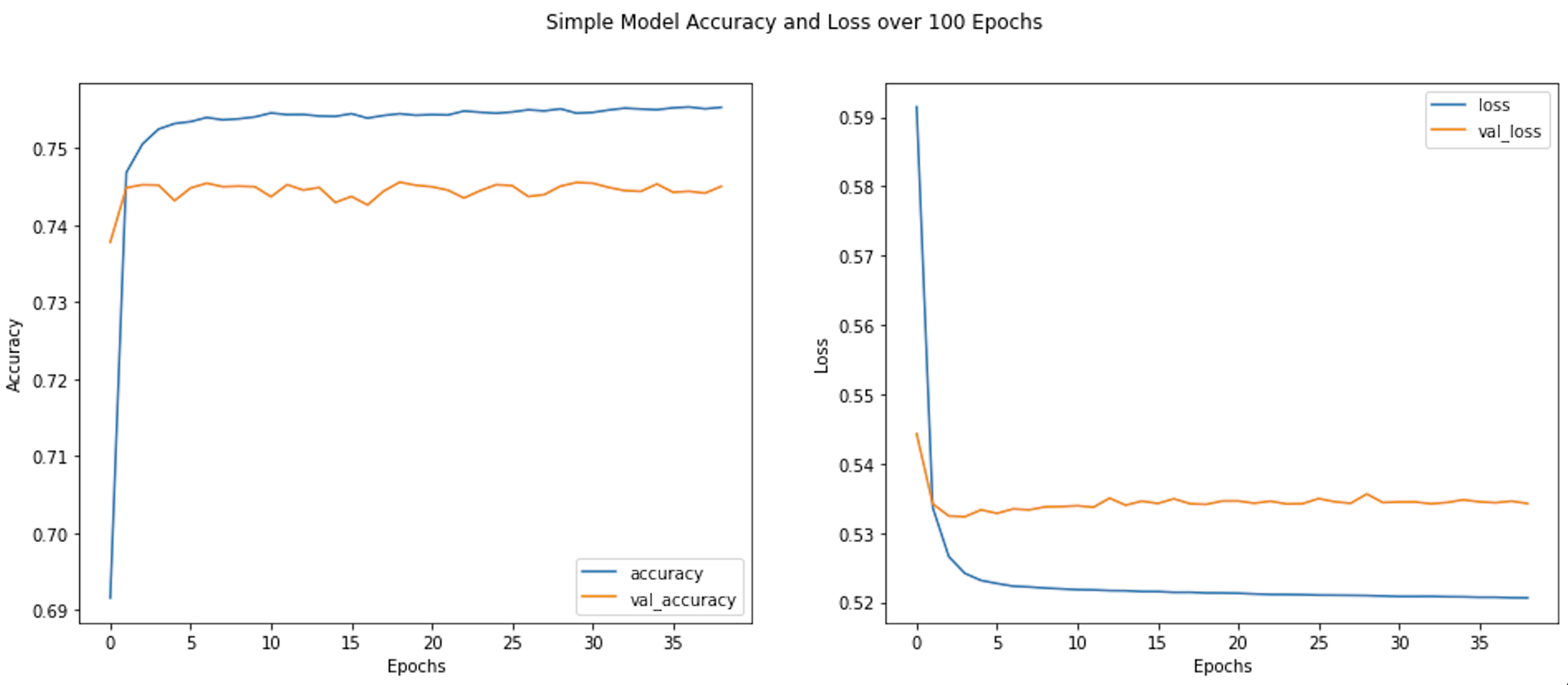
The first model I train is a simple GlobalAveragePooling model. I ran it for 100 epochs, however it early stopped after 39 epochs. Below is the model architecture and the results.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(1, activation='sigmoid')
])
learning_rate = 0.0005
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate),
metrics=['accuracy'])
model.summary()
fit_model_and_show_results(model,'Simple Model',100)
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_5 (Embedding) (None, 26, 16) 64000
global_average_pooling1d_5 (None, 16) 0
(GlobalAveragePooling1D)
dense_5 (Dense) (None, 1) 17
=================================================================
Total params: 64,017
Trainable params: 64,017
Non-trainable params: 0
_________________________________________________________________
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_5 (Embedding) (None, 26, 16) 64000
global_average_pooling1d_5 (None, 16) 0
(GlobalAveragePooling1D)
dense_5 (Dense) (None, 1) 17
=================================================================
Total params: 64,017
Trainable params: 64,017
Non-trainable params: 0
_________________________________________________________________
Epoch 1/100
8445/8445 [==============================] - 36s 4ms/step - loss: 0.5915 - accuracy: 0.6916 - val_loss: 0.5443 - val_accuracy: 0.7378
Epoch 2/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5337 - accuracy: 0.7468 - val_loss: 0.5342 - val_accuracy: 0.7448
Epoch 3/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5266 - accuracy: 0.7505 - val_loss: 0.5325 - val_accuracy: 0.7452
Epoch 4/100
8445/8445 [==============================] - 36s 4ms/step - loss: 0.5242 - accuracy: 0.7525 - val_loss: 0.5323 - val_accuracy: 0.7452
Epoch 5/100
8445/8445 [==============================] - 34s 4ms/step - loss: 0.5232 - accuracy: 0.7532 - val_loss: 0.5333 - val_accuracy: 0.7432
Epoch 6/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5227 - accuracy: 0.7534 - val_loss: 0.5328 - val_accuracy: 0.7448
Epoch 7/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5223 - accuracy: 0.7540 - val_loss: 0.5335 - val_accuracy: 0.7454
Epoch 8/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5222 - accuracy: 0.7537 - val_loss: 0.5333 - val_accuracy: 0.7450
Epoch 9/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5221 - accuracy: 0.7538 - val_loss: 0.5338 - val_accuracy: 0.7450
Epoch 10/100
8445/8445 [==============================] - 36s 4ms/step - loss: 0.5219 - accuracy: 0.7540 - val_loss: 0.5338 - val_accuracy: 0.7450
Epoch 11/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5218 - accuracy: 0.7546 - val_loss: 0.5339 - val_accuracy: 0.7437
Epoch 12/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5218 - accuracy: 0.7543 - val_loss: 0.5337 - val_accuracy: 0.7452
Epoch 13/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5217 - accuracy: 0.7544 - val_loss: 0.5350 - val_accuracy: 0.7445
Epoch 14/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5217 - accuracy: 0.7542 - val_loss: 0.5340 - val_accuracy: 0.7449
Epoch 15/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5216 - accuracy: 0.7541 - val_loss: 0.5346 - val_accuracy: 0.7429
Epoch 16/100
8445/8445 [==============================] - 34s 4ms/step - loss: 0.5216 - accuracy: 0.7545 - val_loss: 0.5343 - val_accuracy: 0.7437
Epoch 17/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5214 - accuracy: 0.7539 - val_loss: 0.5349 - val_accuracy: 0.7426
Epoch 18/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5214 - accuracy: 0.7542 - val_loss: 0.5342 - val_accuracy: 0.7444
Epoch 19/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5214 - accuracy: 0.7545 - val_loss: 0.5341 - val_accuracy: 0.7456
Epoch 20/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5213 - accuracy: 0.7543 - val_loss: 0.5346 - val_accuracy: 0.7452
Epoch 21/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5213 - accuracy: 0.7543 - val_loss: 0.5346 - val_accuracy: 0.7450
Epoch 22/100
8445/8445 [==============================] - 36s 4ms/step - loss: 0.5212 - accuracy: 0.7543 - val_loss: 0.5343 - val_accuracy: 0.7445
Epoch 23/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5211 - accuracy: 0.7548 - val_loss: 0.5346 - val_accuracy: 0.7435
Epoch 24/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5211 - accuracy: 0.7546 - val_loss: 0.5342 - val_accuracy: 0.7445
Epoch 25/100
8445/8445 [==============================] - 34s 4ms/step - loss: 0.5211 - accuracy: 0.7545 - val_loss: 0.5342 - val_accuracy: 0.7452
Epoch 26/100
8445/8445 [==============================] - 32s 4ms/step - loss: 0.5210 - accuracy: 0.7547 - val_loss: 0.5350 - val_accuracy: 0.7451
Epoch 27/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5210 - accuracy: 0.7550 - val_loss: 0.5345 - val_accuracy: 0.7437
Epoch 28/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5210 - accuracy: 0.7548 - val_loss: 0.5343 - val_accuracy: 0.7440
Epoch 29/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5210 - accuracy: 0.7551 - val_loss: 0.5356 - val_accuracy: 0.7450
Epoch 30/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5209 - accuracy: 0.7545 - val_loss: 0.5344 - val_accuracy: 0.7455
Epoch 31/100
8445/8445 [==============================] - 34s 4ms/step - loss: 0.5208 - accuracy: 0.7546 - val_loss: 0.5345 - val_accuracy: 0.7454
Epoch 32/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5208 - accuracy: 0.7549 - val_loss: 0.5345 - val_accuracy: 0.7449
Epoch 33/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5209 - accuracy: 0.7552 - val_loss: 0.5342 - val_accuracy: 0.7445
Epoch 34/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5208 - accuracy: 0.7551 - val_loss: 0.5344 - val_accuracy: 0.7444
Epoch 35/100
8445/8445 [==============================] - 33s 4ms/step - loss: 0.5208 - accuracy: 0.7550 - val_loss: 0.5348 - val_accuracy: 0.7453
Epoch 36/100
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5207 - accuracy: 0.7552 - val_loss: 0.5345 - val_accuracy: 0.7443
Epoch 37/100
8445/8445 [==============================] - 32s 4ms/step - loss: 0.5207 - accuracy: 0.7553 - val_loss: 0.5344 - val_accuracy: 0.7444
Epoch 38/100
8445/8445 [==============================] - 32s 4ms/step - loss: 0.5207 - accuracy: 0.7551 - val_loss: 0.5346 - val_accuracy: 0.7441
Epoch 39/100
8445/8445 [==============================] - 34s 4ms/step - loss: 0.5206 - accuracy: 0.7553 - val_loss: 0.5342 - val_accuracy: 0.7450
Epoch 39: early stopping
CNN Model
The second model is a CNN model with 1 convolution layer. I trained it for 30 epochs, however it stopped early at 28 epochs.
model_cnn = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Conv1D(16, 5, activation='relu'),
tf.keras.layers.GlobalMaxPooling1D(),
tf.keras.layers.Dense(1, activation='sigmoid')
])
learning_rate = 0.0001
model_cnn.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate),
metrics=['accuracy'])
fit_model_and_show_results(model_cnn,'CNN Model',30)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 26, 16) 64000
conv1d (Conv1D) (None, 22, 16) 1296
global_max_pooling1d (Globa (None, 16) 0
lMaxPooling1D)
dense (Dense) (None, 1) 17
=================================================================
Total params: 65,313
Trainable params: 65,313
Non-trainable params: 0
_________________________________________________________________
Epoch 1/30
8445/8445 [==============================] - 43s 4ms/step - loss: 0.6042 - accuracy: 0.6724 - val_loss: 0.5378 - val_accuracy: 0.7386
Epoch 2/30
8445/8445 [==============================] - 35s 4ms/step - loss: 0.5180 - accuracy: 0.7496 - val_loss: 0.5092 - val_accuracy: 0.7524
Epoch 3/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4962 - accuracy: 0.7603 - val_loss: 0.4982 - val_accuracy: 0.7558
Epoch 4/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4851 - accuracy: 0.7667 - val_loss: 0.4928 - val_accuracy: 0.7583
Epoch 5/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4777 - accuracy: 0.7703 - val_loss: 0.4913 - val_accuracy: 0.7591
Epoch 6/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4722 - accuracy: 0.7734 - val_loss: 0.4880 - val_accuracy: 0.7615
Epoch 7/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4675 - accuracy: 0.7758 - val_loss: 0.4868 - val_accuracy: 0.7625
Epoch 8/30
8445/8445 [==============================] - 35s 4ms/step - loss: 0.4633 - accuracy: 0.7790 - val_loss: 0.4860 - val_accuracy: 0.7633
Epoch 9/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4594 - accuracy: 0.7816 - val_loss: 0.4863 - val_accuracy: 0.7627
Epoch 10/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4558 - accuracy: 0.7841 - val_loss: 0.4856 - val_accuracy: 0.7618
Epoch 11/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4522 - accuracy: 0.7863 - val_loss: 0.4857 - val_accuracy: 0.7618
Epoch 12/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4487 - accuracy: 0.7887 - val_loss: 0.4863 - val_accuracy: 0.7616
Epoch 13/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4453 - accuracy: 0.7903 - val_loss: 0.4867 - val_accuracy: 0.7622
Epoch 14/30
8445/8445 [==============================] - 37s 4ms/step - loss: 0.4420 - accuracy: 0.7925 - val_loss: 0.4876 - val_accuracy: 0.7616
Epoch 15/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4387 - accuracy: 0.7948 - val_loss: 0.4882 - val_accuracy: 0.7611
Epoch 16/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4356 - accuracy: 0.7967 - val_loss: 0.4890 - val_accuracy: 0.7600
Epoch 17/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4325 - accuracy: 0.7988 - val_loss: 0.4902 - val_accuracy: 0.7604
Epoch 18/30
8445/8445 [==============================] - 38s 4ms/step - loss: 0.4293 - accuracy: 0.8008 - val_loss: 0.4918 - val_accuracy: 0.7598
Epoch 19/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4263 - accuracy: 0.8025 - val_loss: 0.4935 - val_accuracy: 0.7604
Epoch 20/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4234 - accuracy: 0.8046 - val_loss: 0.4950 - val_accuracy: 0.7593
Epoch 21/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4204 - accuracy: 0.8066 - val_loss: 0.4963 - val_accuracy: 0.7588
Epoch 22/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4175 - accuracy: 0.8083 - val_loss: 0.4984 - val_accuracy: 0.7577
Epoch 23/30
8445/8445 [==============================] - 37s 4ms/step - loss: 0.4147 - accuracy: 0.8100 - val_loss: 0.5000 - val_accuracy: 0.7575
Epoch 24/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4119 - accuracy: 0.8122 - val_loss: 0.5009 - val_accuracy: 0.7571
Epoch 25/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4092 - accuracy: 0.8136 - val_loss: 0.5033 - val_accuracy: 0.7563
Epoch 26/30
8445/8445 [==============================] - 34s 4ms/step - loss: 0.4066 - accuracy: 0.8154 - val_loss: 0.5054 - val_accuracy: 0.7554
Epoch 27/30
8445/8445 [==============================] - 36s 4ms/step - loss: 0.4041 - accuracy: 0.8170 - val_loss: 0.5079 - val_accuracy: 0.7541
Epoch 28/30
8445/8445 [==============================] - 35s 4ms/step - loss: 0.4016 - accuracy: 0.8184 - val_loss: 0.5094 - val_accuracy: 0.7538
Epoch 28: early stopping

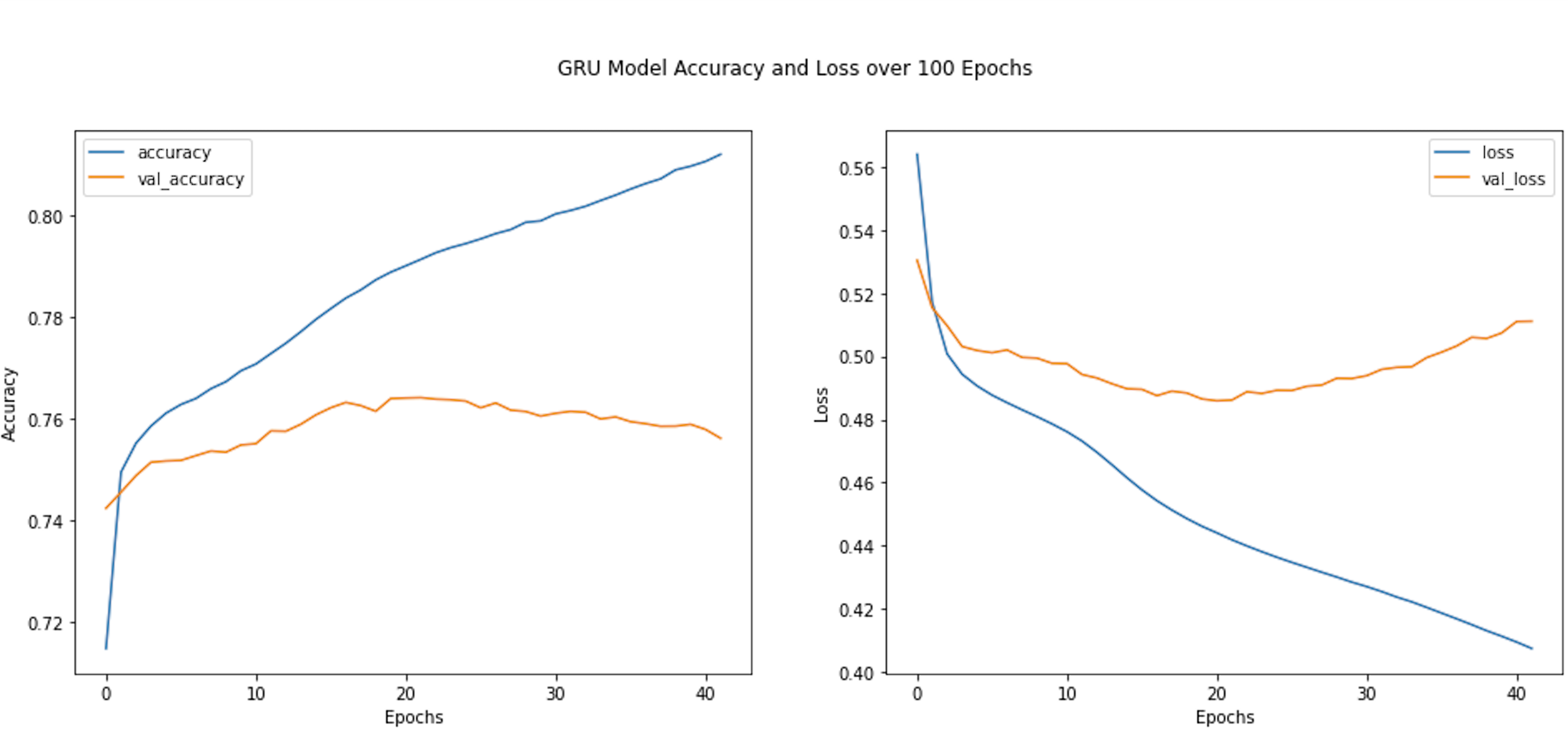
GRU Model
Next I trained the data on a GRU model for 100 epochs. The model had an early stop at 42 epochs.
model_gru = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(32)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
learning_rate = 0.0001
model_gru.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate),
metrics=['accuracy'])
fit_model_and_show_results(model_gru, 'GRU Model', 100)
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_6 (Embedding) (None, 26, 16) 64000
bidirectional (Bidirectiona (None, 64) 9600
l)
dense_6 (Dense) (None, 1) 65
=================================================================
Total params: 73,665
Trainable params: 73,665
Non-trainable params: 0
_________________________________________________________________
Epoch 1/100
8445/8445 [==============================] - 73s 8ms/step - loss: 0.5641 - accuracy: 0.7149 - val_loss: 0.5305 - val_accuracy: 0.7424
Epoch 2/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.5173 - accuracy: 0.7495 - val_loss: 0.5155 - val_accuracy: 0.7456
Epoch 3/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.5008 - accuracy: 0.7552 - val_loss: 0.5098 - val_accuracy: 0.7488
Epoch 4/100
8445/8445 [==============================] - 66s 8ms/step - loss: 0.4944 - accuracy: 0.7586 - val_loss: 0.5032 - val_accuracy: 0.7515
Epoch 5/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4906 - accuracy: 0.7611 - val_loss: 0.5019 - val_accuracy: 0.7517
Epoch 6/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4877 - accuracy: 0.7628 - val_loss: 0.5012 - val_accuracy: 0.7518
Epoch 7/100
8445/8445 [==============================] - 66s 8ms/step - loss: 0.4853 - accuracy: 0.7640 - val_loss: 0.5021 - val_accuracy: 0.7528
Epoch 8/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4831 - accuracy: 0.7659 - val_loss: 0.4997 - val_accuracy: 0.7537
Epoch 9/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4809 - accuracy: 0.7673 - val_loss: 0.4995 - val_accuracy: 0.7534
Epoch 10/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4786 - accuracy: 0.7694 - val_loss: 0.4978 - val_accuracy: 0.7548
Epoch 11/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4761 - accuracy: 0.7707 - val_loss: 0.4977 - val_accuracy: 0.7551
Epoch 12/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4731 - accuracy: 0.7728 - val_loss: 0.4943 - val_accuracy: 0.7576
Epoch 13/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4696 - accuracy: 0.7748 - val_loss: 0.4931 - val_accuracy: 0.7575
Epoch 14/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4656 - accuracy: 0.7771 - val_loss: 0.4913 - val_accuracy: 0.7589
Epoch 15/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4615 - accuracy: 0.7795 - val_loss: 0.4897 - val_accuracy: 0.7608
Epoch 16/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4576 - accuracy: 0.7816 - val_loss: 0.4895 - val_accuracy: 0.7622
Epoch 17/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4542 - accuracy: 0.7837 - val_loss: 0.4875 - val_accuracy: 0.7632
Epoch 18/100
8445/8445 [==============================] - 63s 7ms/step - loss: 0.4512 - accuracy: 0.7853 - val_loss: 0.4890 - val_accuracy: 0.7626
Epoch 19/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4485 - accuracy: 0.7873 - val_loss: 0.4884 - val_accuracy: 0.7615
Epoch 20/100
8445/8445 [==============================] - 63s 8ms/step - loss: 0.4461 - accuracy: 0.7888 - val_loss: 0.4865 - val_accuracy: 0.7640
Epoch 21/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4440 - accuracy: 0.7900 - val_loss: 0.4859 - val_accuracy: 0.7641
Epoch 22/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4418 - accuracy: 0.7913 - val_loss: 0.4861 - val_accuracy: 0.7641
Epoch 23/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4398 - accuracy: 0.7926 - val_loss: 0.4888 - val_accuracy: 0.7638
Epoch 24/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4380 - accuracy: 0.7936 - val_loss: 0.4882 - val_accuracy: 0.7637
Epoch 25/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4363 - accuracy: 0.7944 - val_loss: 0.4892 - val_accuracy: 0.7635
Epoch 26/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4346 - accuracy: 0.7953 - val_loss: 0.4892 - val_accuracy: 0.7621
Epoch 27/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4331 - accuracy: 0.7963 - val_loss: 0.4905 - val_accuracy: 0.7631
Epoch 28/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4315 - accuracy: 0.7971 - val_loss: 0.4909 - val_accuracy: 0.7617
Epoch 29/100
8445/8445 [==============================] - 63s 7ms/step - loss: 0.4300 - accuracy: 0.7985 - val_loss: 0.4931 - val_accuracy: 0.7614
Epoch 30/100
8445/8445 [==============================] - 63s 7ms/step - loss: 0.4284 - accuracy: 0.7988 - val_loss: 0.4930 - val_accuracy: 0.7605
Epoch 31/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4269 - accuracy: 0.8002 - val_loss: 0.4939 - val_accuracy: 0.7611
Epoch 32/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4253 - accuracy: 0.8009 - val_loss: 0.4959 - val_accuracy: 0.7615
Epoch 33/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4236 - accuracy: 0.8017 - val_loss: 0.4965 - val_accuracy: 0.7613
Epoch 34/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4221 - accuracy: 0.8028 - val_loss: 0.4967 - val_accuracy: 0.7600
Epoch 35/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4203 - accuracy: 0.8039 - val_loss: 0.4996 - val_accuracy: 0.7604
Epoch 36/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4185 - accuracy: 0.8051 - val_loss: 0.5014 - val_accuracy: 0.7594
Epoch 37/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4167 - accuracy: 0.8062 - val_loss: 0.5033 - val_accuracy: 0.7590
Epoch 38/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4149 - accuracy: 0.8071 - val_loss: 0.5061 - val_accuracy: 0.7585
Epoch 39/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4129 - accuracy: 0.8088 - val_loss: 0.5057 - val_accuracy: 0.7585
Epoch 40/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4112 - accuracy: 0.8096 - val_loss: 0.5074 - val_accuracy: 0.7589
Epoch 41/100
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4093 - accuracy: 0.8105 - val_loss: 0.5111 - val_accuracy: 0.7579
Epoch 42/100
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4073 - accuracy: 0.8119 - val_loss: 0.5112 - val_accuracy: 0.7562
Epoch 42: early stopping
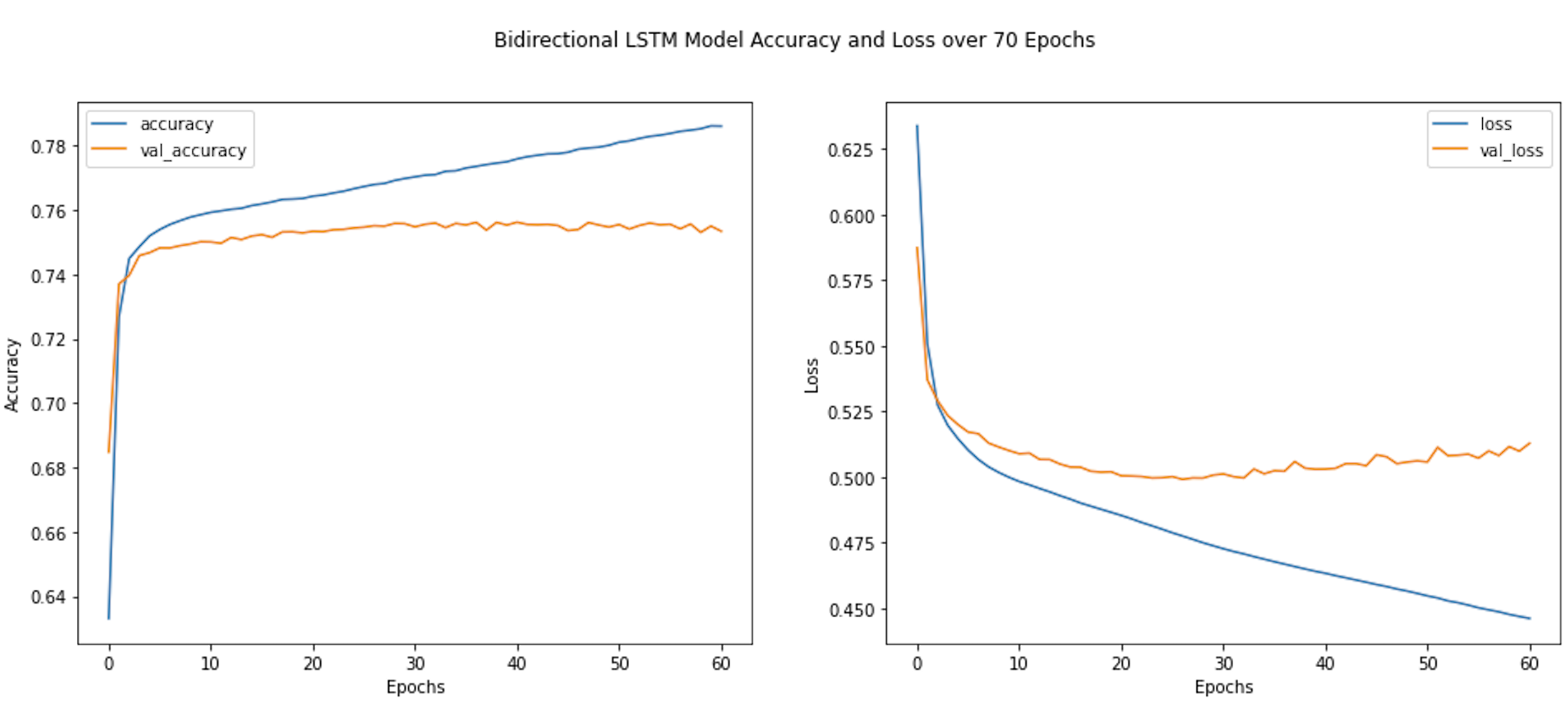
Bidirectional LSTM
The next model I trained was a bidirectional LSTM model with one layer. The model was trained for 70 epochs but stopped at 61.
model_bidi_lstm = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
learning_rate = 0.00003
model_bidi_lstm.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate),
metrics=['accuracy'])
fit_model_and_show_results(model_bidi_lstm, 'Bidirectional LSTM Model',70)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 26, 16) 64000
bidirectional (Bidirectiona (None, 32) 4224
l)
dense (Dense) (None, 1) 33
=================================================================
Total params: 68,257
Trainable params: 68,257
Non-trainable params: 0
_________________________________________________________________
Epoch 1/70
8445/8445 [==============================] - 76s 8ms/step - loss: 0.6338 - accuracy: 0.6332 - val_loss: 0.5873 - val_accuracy: 0.6849
Epoch 2/70
8445/8445 [==============================] - 69s 8ms/step - loss: 0.5509 - accuracy: 0.7267 - val_loss: 0.5370 - val_accuracy: 0.7370
Epoch 3/70
8445/8445 [==============================] - 67s 8ms/step - loss: 0.5274 - accuracy: 0.7449 - val_loss: 0.5291 - val_accuracy: 0.7397
Epoch 4/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.5197 - accuracy: 0.7486 - val_loss: 0.5234 - val_accuracy: 0.7459
Epoch 5/70
8445/8445 [==============================] - 66s 8ms/step - loss: 0.5146 - accuracy: 0.7520 - val_loss: 0.5200 - val_accuracy: 0.7468
Epoch 6/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.5102 - accuracy: 0.7540 - val_loss: 0.5171 - val_accuracy: 0.7482
Epoch 7/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.5067 - accuracy: 0.7555 - val_loss: 0.5165 - val_accuracy: 0.7482
Epoch 8/70
8445/8445 [==============================] - 69s 8ms/step - loss: 0.5038 - accuracy: 0.7567 - val_loss: 0.5129 - val_accuracy: 0.7489
Epoch 9/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.5017 - accuracy: 0.7578 - val_loss: 0.5114 - val_accuracy: 0.7495
Epoch 10/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4999 - accuracy: 0.7586 - val_loss: 0.5100 - val_accuracy: 0.7502
Epoch 11/70
8445/8445 [==============================] - 66s 8ms/step - loss: 0.4983 - accuracy: 0.7593 - val_loss: 0.5088 - val_accuracy: 0.7501
Epoch 12/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4970 - accuracy: 0.7597 - val_loss: 0.5091 - val_accuracy: 0.7497
Epoch 13/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4956 - accuracy: 0.7602 - val_loss: 0.5067 - val_accuracy: 0.7515
Epoch 14/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4943 - accuracy: 0.7605 - val_loss: 0.5066 - val_accuracy: 0.7508
Epoch 15/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4929 - accuracy: 0.7614 - val_loss: 0.5049 - val_accuracy: 0.7519
Epoch 16/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4916 - accuracy: 0.7619 - val_loss: 0.5038 - val_accuracy: 0.7524
Epoch 17/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4901 - accuracy: 0.7625 - val_loss: 0.5037 - val_accuracy: 0.7515
Epoch 18/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4889 - accuracy: 0.7633 - val_loss: 0.5022 - val_accuracy: 0.7532
Epoch 19/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4877 - accuracy: 0.7634 - val_loss: 0.5018 - val_accuracy: 0.7532
Epoch 20/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4865 - accuracy: 0.7636 - val_loss: 0.5020 - val_accuracy: 0.7529
Epoch 21/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4853 - accuracy: 0.7643 - val_loss: 0.5004 - val_accuracy: 0.7534
Epoch 22/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4841 - accuracy: 0.7647 - val_loss: 0.5003 - val_accuracy: 0.7533
Epoch 23/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4827 - accuracy: 0.7653 - val_loss: 0.5002 - val_accuracy: 0.7539
Epoch 24/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4814 - accuracy: 0.7659 - val_loss: 0.4996 - val_accuracy: 0.7540
Epoch 25/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4801 - accuracy: 0.7666 - val_loss: 0.4997 - val_accuracy: 0.7544
Epoch 26/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4787 - accuracy: 0.7673 - val_loss: 0.5001 - val_accuracy: 0.7547
Epoch 27/70
8445/8445 [==============================] - 63s 8ms/step - loss: 0.4775 - accuracy: 0.7679 - val_loss: 0.4991 - val_accuracy: 0.7551
Epoch 28/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4762 - accuracy: 0.7683 - val_loss: 0.4996 - val_accuracy: 0.7550
Epoch 29/70
8445/8445 [==============================] - 68s 8ms/step - loss: 0.4749 - accuracy: 0.7692 - val_loss: 0.4996 - val_accuracy: 0.7558
Epoch 30/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4738 - accuracy: 0.7698 - val_loss: 0.5007 - val_accuracy: 0.7558
Epoch 31/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4727 - accuracy: 0.7703 - val_loss: 0.5011 - val_accuracy: 0.7548
Epoch 32/70
8445/8445 [==============================] - 67s 8ms/step - loss: 0.4716 - accuracy: 0.7708 - val_loss: 0.5001 - val_accuracy: 0.7556
Epoch 33/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4707 - accuracy: 0.7710 - val_loss: 0.4996 - val_accuracy: 0.7560
Epoch 34/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4696 - accuracy: 0.7720 - val_loss: 0.5030 - val_accuracy: 0.7546
Epoch 35/70
8445/8445 [==============================] - 63s 8ms/step - loss: 0.4687 - accuracy: 0.7722 - val_loss: 0.5012 - val_accuracy: 0.7558
Epoch 36/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4677 - accuracy: 0.7731 - val_loss: 0.5024 - val_accuracy: 0.7554
Epoch 37/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4668 - accuracy: 0.7736 - val_loss: 0.5022 - val_accuracy: 0.7562
Epoch 38/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4659 - accuracy: 0.7741 - val_loss: 0.5059 - val_accuracy: 0.7538
Epoch 39/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4649 - accuracy: 0.7746 - val_loss: 0.5034 - val_accuracy: 0.7562
Epoch 40/70
8445/8445 [==============================] - 63s 8ms/step - loss: 0.4641 - accuracy: 0.7750 - val_loss: 0.5029 - val_accuracy: 0.7553
Epoch 41/70
8445/8445 [==============================] - 63s 8ms/step - loss: 0.4633 - accuracy: 0.7759 - val_loss: 0.5030 - val_accuracy: 0.7562
Epoch 42/70
8445/8445 [==============================] - 65s 8ms/step - loss: 0.4624 - accuracy: 0.7766 - val_loss: 0.5033 - val_accuracy: 0.7555
Epoch 43/70
8445/8445 [==============================] - 63s 8ms/step - loss: 0.4616 - accuracy: 0.7770 - val_loss: 0.5051 - val_accuracy: 0.7554
Epoch 44/70
8445/8445 [==============================] - 63s 7ms/step - loss: 0.4607 - accuracy: 0.7774 - val_loss: 0.5051 - val_accuracy: 0.7556
Epoch 45/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4599 - accuracy: 0.7775 - val_loss: 0.5043 - val_accuracy: 0.7552
Epoch 46/70
8445/8445 [==============================] - 63s 7ms/step - loss: 0.4590 - accuracy: 0.7780 - val_loss: 0.5085 - val_accuracy: 0.7536
Epoch 47/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4582 - accuracy: 0.7789 - val_loss: 0.5077 - val_accuracy: 0.7540
Epoch 48/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4573 - accuracy: 0.7793 - val_loss: 0.5051 - val_accuracy: 0.7561
Epoch 49/70
8445/8445 [==============================] - 63s 8ms/step - loss: 0.4565 - accuracy: 0.7795 - val_loss: 0.5057 - val_accuracy: 0.7554
Epoch 50/70
8445/8445 [==============================] - 63s 7ms/step - loss: 0.4556 - accuracy: 0.7801 - val_loss: 0.5061 - val_accuracy: 0.7547
Epoch 51/70
8445/8445 [==============================] - 63s 7ms/step - loss: 0.4547 - accuracy: 0.7811 - val_loss: 0.5057 - val_accuracy: 0.7555
Epoch 52/70
8445/8445 [==============================] - 69s 8ms/step - loss: 0.4539 - accuracy: 0.7815 - val_loss: 0.5113 - val_accuracy: 0.7541
Epoch 53/70
8445/8445 [==============================] - 67s 8ms/step - loss: 0.4528 - accuracy: 0.7823 - val_loss: 0.5081 - val_accuracy: 0.7552
Epoch 54/70
8445/8445 [==============================] - 63s 7ms/step - loss: 0.4521 - accuracy: 0.7829 - val_loss: 0.5083 - val_accuracy: 0.7560
Epoch 55/70
8445/8445 [==============================] - 68s 8ms/step - loss: 0.4512 - accuracy: 0.7833 - val_loss: 0.5087 - val_accuracy: 0.7554
Epoch 56/70
8445/8445 [==============================] - 68s 8ms/step - loss: 0.4501 - accuracy: 0.7838 - val_loss: 0.5072 - val_accuracy: 0.7556
Epoch 57/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4494 - accuracy: 0.7845 - val_loss: 0.5099 - val_accuracy: 0.7542
Epoch 58/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4486 - accuracy: 0.7848 - val_loss: 0.5082 - val_accuracy: 0.7557
Epoch 59/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4476 - accuracy: 0.7853 - val_loss: 0.5116 - val_accuracy: 0.7531
Epoch 60/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4468 - accuracy: 0.7861 - val_loss: 0.5098 - val_accuracy: 0.7550
Epoch 61/70
8445/8445 [==============================] - 64s 8ms/step - loss: 0.4461 - accuracy: 0.7861 - val_loss: 0.5128 - val_accuracy: 0.7534
Epoch 61: early stopping
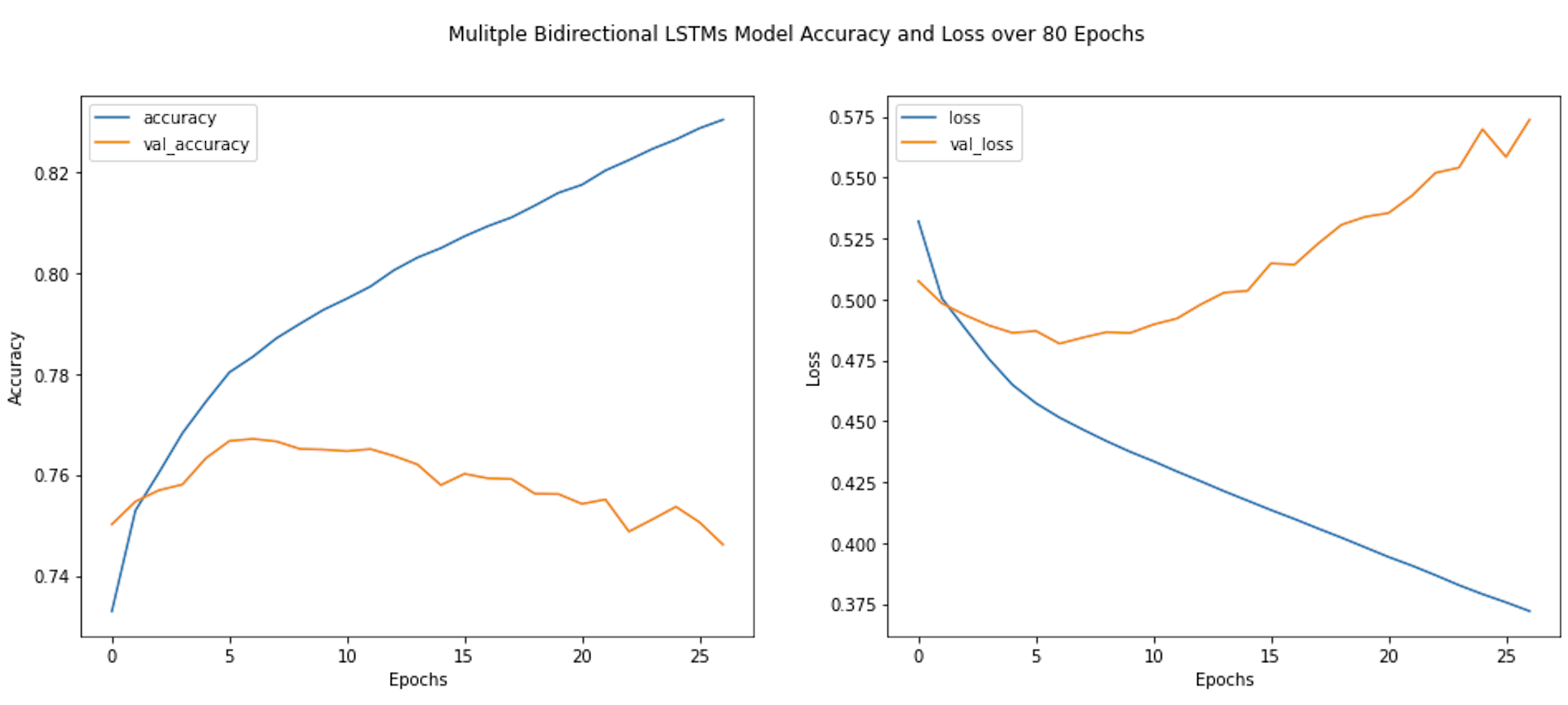
Mulitple Bidirectional LSTMs
Finally, I trained a model with two bidirectional LSTM layers. The model was trained for 80 epochs but early stopped at 27.
model_multiple_bidi_lstm = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim,
return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
learning_rate = 0.0003
model_multiple_bidi_lstm.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate),
metrics=['accuracy'])
fit_model_and_show_results(model_multiple_bidi_lstm, 'Mulitple Bidirectional LSTMs Model', 80)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 26, 16) 64000
bidirectional (Bidirectiona (None, 26, 32) 4224
l)
bidirectional_1 (Bidirectio (None, 32) 6272
nal)
dense (Dense) (None, 1) 33
=================================================================
Total params: 74,529
Trainable params: 74,529
Non-trainable params: 0
_________________________________________________________________
Epoch 1/80
8445/8445 [==============================] - 108s 12ms/step - loss: 0.5320 - accuracy: 0.7330 - val_loss: 0.5075 - val_accuracy: 0.7502
Epoch 2/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.5004 - accuracy: 0.7529 - val_loss: 0.4983 - val_accuracy: 0.7547
Epoch 3/80
8445/8445 [==============================] - 95s 11ms/step - loss: 0.4878 - accuracy: 0.7604 - val_loss: 0.4934 - val_accuracy: 0.7569
Epoch 4/80
8445/8445 [==============================] - 94s 11ms/step - loss: 0.4755 - accuracy: 0.7682 - val_loss: 0.4893 - val_accuracy: 0.7581
Epoch 5/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.4649 - accuracy: 0.7745 - val_loss: 0.4862 - val_accuracy: 0.7633
Epoch 6/80
8445/8445 [==============================] - 95s 11ms/step - loss: 0.4573 - accuracy: 0.7803 - val_loss: 0.4870 - val_accuracy: 0.7667
Epoch 7/80
8445/8445 [==============================] - 96s 11ms/step - loss: 0.4514 - accuracy: 0.7834 - val_loss: 0.4818 - val_accuracy: 0.7671
Epoch 8/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.4465 - accuracy: 0.7870 - val_loss: 0.4843 - val_accuracy: 0.7666
Epoch 9/80
8445/8445 [==============================] - 94s 11ms/step - loss: 0.4418 - accuracy: 0.7899 - val_loss: 0.4865 - val_accuracy: 0.7651
Epoch 10/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.4374 - accuracy: 0.7927 - val_loss: 0.4861 - val_accuracy: 0.7650
Epoch 11/80
8445/8445 [==============================] - 94s 11ms/step - loss: 0.4335 - accuracy: 0.7949 - val_loss: 0.4897 - val_accuracy: 0.7647
Epoch 12/80
8445/8445 [==============================] - 94s 11ms/step - loss: 0.4293 - accuracy: 0.7973 - val_loss: 0.4921 - val_accuracy: 0.7651
Epoch 13/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.4253 - accuracy: 0.8005 - val_loss: 0.4978 - val_accuracy: 0.7637
Epoch 14/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.4212 - accuracy: 0.8030 - val_loss: 0.5027 - val_accuracy: 0.7620
Epoch 15/80
8445/8445 [==============================] - 96s 11ms/step - loss: 0.4173 - accuracy: 0.8049 - val_loss: 0.5035 - val_accuracy: 0.7580
Epoch 16/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.4135 - accuracy: 0.8072 - val_loss: 0.5147 - val_accuracy: 0.7602
Epoch 17/80
8445/8445 [==============================] - 94s 11ms/step - loss: 0.4098 - accuracy: 0.8092 - val_loss: 0.5142 - val_accuracy: 0.7593
Epoch 18/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.4059 - accuracy: 0.8109 - val_loss: 0.5228 - val_accuracy: 0.7592
Epoch 19/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.4021 - accuracy: 0.8133 - val_loss: 0.5306 - val_accuracy: 0.7563
Epoch 20/80
8445/8445 [==============================] - 94s 11ms/step - loss: 0.3982 - accuracy: 0.8158 - val_loss: 0.5338 - val_accuracy: 0.7562
Epoch 21/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.3942 - accuracy: 0.8174 - val_loss: 0.5354 - val_accuracy: 0.7542
Epoch 22/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.3906 - accuracy: 0.8202 - val_loss: 0.5426 - val_accuracy: 0.7551
Epoch 23/80
8445/8445 [==============================] - 94s 11ms/step - loss: 0.3867 - accuracy: 0.8223 - val_loss: 0.5519 - val_accuracy: 0.7488
Epoch 24/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.3826 - accuracy: 0.8245 - val_loss: 0.5540 - val_accuracy: 0.7512
Epoch 25/80
8445/8445 [==============================] - 92s 11ms/step - loss: 0.3789 - accuracy: 0.8264 - val_loss: 0.5698 - val_accuracy: 0.7537
Epoch 26/80
8445/8445 [==============================] - 94s 11ms/step - loss: 0.3756 - accuracy: 0.8286 - val_loss: 0.5584 - val_accuracy: 0.7506
Epoch 27/80
8445/8445 [==============================] - 93s 11ms/step - loss: 0.3720 - accuracy: 0.8303 - val_loss: 0.5737 - val_accuracy: 0.7462
Epoch 27: early stopping
Conclusions and Next Steps
Taking a look at the results of the training, the mulitiple bidirectional LSTM model appeared to have the best validation accuracy at its 7th epoch with a validation accuracy of 76.71% before before overfitting occurred. This is followed by the GRU, which had the second best validation accuracy at its 21st epoch with a validation accuracy of 76.41%.
Taking a look at the data, my next steps would include seeing if I could boost the validation accuracy of the mulitple bidirectional LSTM model. To do this, I can vary the dropout rate, perform a lasso and/or ridge regression, changing the vocabulary size, and adjusting the learning rate. I could also perform a GridSearch across these hyperparameters to automate this process. I could also perform several other data manipulation techniques when preparing the data, including lemmitization, tf-idf analysis, and n-gram analysis.